

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico .svg)


 KI und Machine Learning revolutionieren unsere Welt: Längst haben personalisierte Kaufempfehlungen, Natural Language Processing und Gesichtserkennung Einzug in unser tägliches Leben gehalten. In anderen Bereichen steht die Nutzung von Künstlicher Intelligenz und Machine Learning noch am Anfang. Klar ist: auch wir Testverantwortlichen werden uns damit auseinandersetzen müssen, was Softwarequalität in diesem Zusammenhang bedeutet.
KI und Machine Learning revolutionieren unsere Welt: Längst haben personalisierte Kaufempfehlungen, Natural Language Processing und Gesichtserkennung Einzug in unser tägliches Leben gehalten. In anderen Bereichen steht die Nutzung von Künstlicher Intelligenz und Machine Learning noch am Anfang. Klar ist: auch wir Testverantwortlichen werden uns damit auseinandersetzen müssen, was Softwarequalität in diesem Zusammenhang bedeutet.
Als Einstieg in das Thema Qualitätsbewertung für Machine Learning, habe ich daher hier einen kurzen Überblick über die wichtigsten Qualitätskriterien zusammengetragen.
Die Theorien und Mathematischen Grundlagen hinter maschinellem Lernen sind natürlich weitaus umfassender, als sich hier berücksichtigen lässt. Auch finden derzeit viele spannende Entwicklungen statt. Um den Einstieg überschaubar zu halten, beziehe ich mich hier auf das Deep Learning, soweit eine Einschränkung notwendig ist.
Was bedeutet überhaupt Machine Learning?
Stark vereinfacht sind typische Problemstellungen, die sich mittels Machine Learning (insbesondere mit Deep Learning) lösen lassen:
- Erkennen von Mustern in Datenreihen und Vorhersage nächster Werte (z.B. Ableitung von Kaufempfehlungen aus der Einkaufshistorie)
- Clustern von Datenmengen und Zuordnen zu Kategorien (z.B. bei Bild- bzw. Gesichtserkennung)
- Erkennung von Abweichungen vom Normalverhalten (z.B. Erkennung von Störeinflüssen im Betrieb)
Für all diese Anwendungen gilt, dass auf Basis einer Menge von Eingabedaten ein Modell trainiert und konfiguriert wird. Mit diesem Modell wird dann die Wahrscheinlichkeit für verschiedene mögliche Ergebnisse ermittelt. Das wahrscheinliche Ergebnis stimmt folglich nicht in jedem Fall mit dem tatsächlich korrekten Ergebnis überein.

Qualitätskriterien für Machine Learning
Aus den genannten Eigenschaften ergeben sich Qualitätskriterien, die je nach System unterschiedliche Bedeutung haben können:
1. Accuracy
Wichtigste Eigenschaft eines Machine Learning Algorithmus ist die Treffgenauigkeit der Kategoriezuordnung bzw. Vorhersage. Die erreichbare Genauigkeit hängt hierbei vom konkreten Problem, vom verwendeten Modell sowie Art und Anzahl der Eingangsdaten ab.
Selbstverständlich ist das Ziel, die höchstmögliche Genauigkeit zu erreichen. Es kann aber sinnvoll sein, eine notwendige Mindestgenauigkeit zu definieren, die erreicht werden muss.
Nehmen wir zum Beispiel ein System zur Erkennung von Betrugsversuchen: Lehnt das System gültige Eingaben als Betrugsversuch ab (False Positive) so kann es schon bei wenigen Fehleinschätzungen zu schlechtem Kundenfeedback kommen.
Falsche Kaufempfehlungen einer Software, die beim Online-Shopping unterstützt, haben hingegen weit weniger Auswirkung.
2. Robustness
Ein wichtiger Einflussfaktor für die Ergebnisqualität ist die Robustheit gegenüber unterschiedlichen Eingaben. Hierbei gilt es insbesondere 2 gegensätzliche Probleme zu vermeiden: Bias und Overfitting.
- Bias liegt vor, wenn Eingaben bevorzugt zu einer Ergebniskategorie zugeordnet werden und hierbei zusätzliche Informationen aus den Eingaben unberücksichtigt bleiben. Man spricht auch von Unteranpassung. In den letzten Jahren gab es einige prominente Beispiele dazu.
- Overfitting (Overfitting, auch Overtraining) liegt vor, wenn irrelevante oder wenig relevante Eigenschaften in den Entscheidungsprozess einbezogen und übermäßig gewichtet werden. Problem: Bei prognostizierten Werten ergibt sich eine hohe Abweichung von den tatsächlichen Werten, wenn nicht alle erwarteten Eigenschaften übereinstimmen.
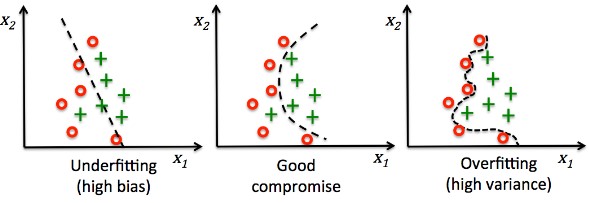
Abhängig vom zu lösenden Problem ist die Anforderung an Robustheit gegenüber Rauschen (Noise, irrelevanter Information) und die tatsächliche Varianz in den Eingabedaten sehr unterschiedlich. Aufgrund des bias-variance-tradeoffs lässt sich aber nicht beides gleichzeitig maximieren. Wissen über die möglichen Eingaben und konkrete Qualitätsziele sind daher unerlässlich.
3. Lerneffizienz / Anpassung
Wie viele Lernzyklen / Eingabedaten benötigt das System um akkurate Zuordnungen bzw. Vorhersagen zu erreichen? Auch dies ist ein Qualitätskriterium für Machine Learning. Mit jeder neuen Eingabe d.h. mit jedem Lernzyklus korrigiert das System die Gewichtung der Einflussfaktoren. Je nach Modell und Algorithmus erreicht es damit schneller oder langsamer eine optimale Genauigkeit.
Welche Anforderungen an die Lerngeschwindigkeit bestehen, hängt oft damit zusammen, wie viele Daten (labeled und unlabeled) für das Training zur Verfügung stehen. Im Allgemeinen heißt es: auch langsamer lernende Systeme erreichen eine hohe Genauigkeit, wenn sie nur genügend Trainingsdaten zur Verfügung haben. Für bestimmte häufige Probleme, z.B. Bilderkennung, gibt es sogar schon vor-trainierte Modelle.
4. Performance
Letztendlich spielt auch die Performance des Systems eine Rolle, d.h. welche Anforderungen werden an Speicher und Rechenleistung gestellt werden, um Preprocessing, Training aber auch die eigentliche Problemlösung in akzeptabler Zeit abzuschließen.
Fazit
All das zeigt: es kommen spannende Zeiten auf uns Tester zu. Qualitätskriterien zu definieren und zu kennen ist ein wichtiger Schritt. Sie tatsächlich zu überprüfen, wird eine ganz neue Herausforderung.

