

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


I have had the same mobile number for the last 20 years now and it feels good to be part of this select club. However, I had switched to a different mobile operator after the first 5 years. Reason? Unsatisfactory services like frequent call drops, slow internet connection and limited coverage in many areas. But these unpleasant customer experiences helped me learn something: Had my original operator provided high-quality services, I could well have stayed loyal to it for the next 15 years (and more).
Unreliability and uncertainty are the two most common problems that many of us have faced in similar scenarios. It could be as simple as reading the news online or something more complex like selecting a cloud vendor. If the platform has a frequent outage and gives regular downtime, what would be your next step? Of course, in today’s world where we are spoilt for choices, your natural reaction would be to change the platform or vendor or technology partner.
Even the latest technology can be vulnerable
One common misconception within engineering teams nowadays is that if they use the latest technology like containers’ orchestration or matured cloud vendors, they have an up-to-date system with fail-proof mechanisms. Well, one needs to review this objectively because it is not just about choosing an advanced data center or cloud vendor but also about how the application will behave when exposed to a multitude of turbulence factors.
On February 28th 2017, the 4-hour Amazon S3 service disruption in Northern Virginia rattled the entire industry. Apart from enforcing disruption in the services of many big companies, it also made enterprises re-assess their cloud maturity. We learned that even the most experienced cloud vendor could be vulnerable to failure.
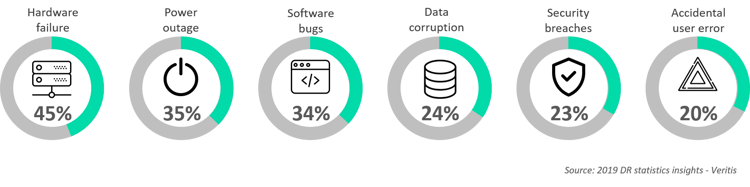
In a report published by Veritis (on 2019 DR statistics insights), 45% of all breakdowns happen because of hardware failure, 35% because of a power outage, 34% because of software failure, 24% because of data corruption, 23% because of security breaches, and 20% due to accidental user error.
The priority areas to focus on
When considering the priority areas to choose or the resilience parameters to focus on, the answer is quite elementary and simple - you need to cover them all! This is because all of them have a common denominator called customer satisfaction, which cannot be compromised, irrespective of any turbulence in the ecosystem.
The Syncsort State of Resilience Report 2018 shows that enterprises are now focusing on availability (67%) as the top measure of IT performance, followed by application performance (49%).
Preparing the resilience matrix will certainly help organizations focus on the priority fixes and in understanding how they can gradually reduce the blast surface. This, however, is an activity of continuous improvement that should be integrated within the standard delivery process.
A framework to orchestrate chaos engineering
Overall, it would be best to leverage a DevOps strategy that can work on different turbulence factors to make our systems resilient to any breakdown. Chaos engineering aims at identifying the vulnerabilities within the system by using resilience testing. But combining it with DevOps not only detects any turbulence effectively but also helps in fixing it in a phased manner. Remember, it is a joint effort where the consensus of all the system architects – Security, Application, Infra, Testing, and Database – is needed to ensure a robust resilience framework.
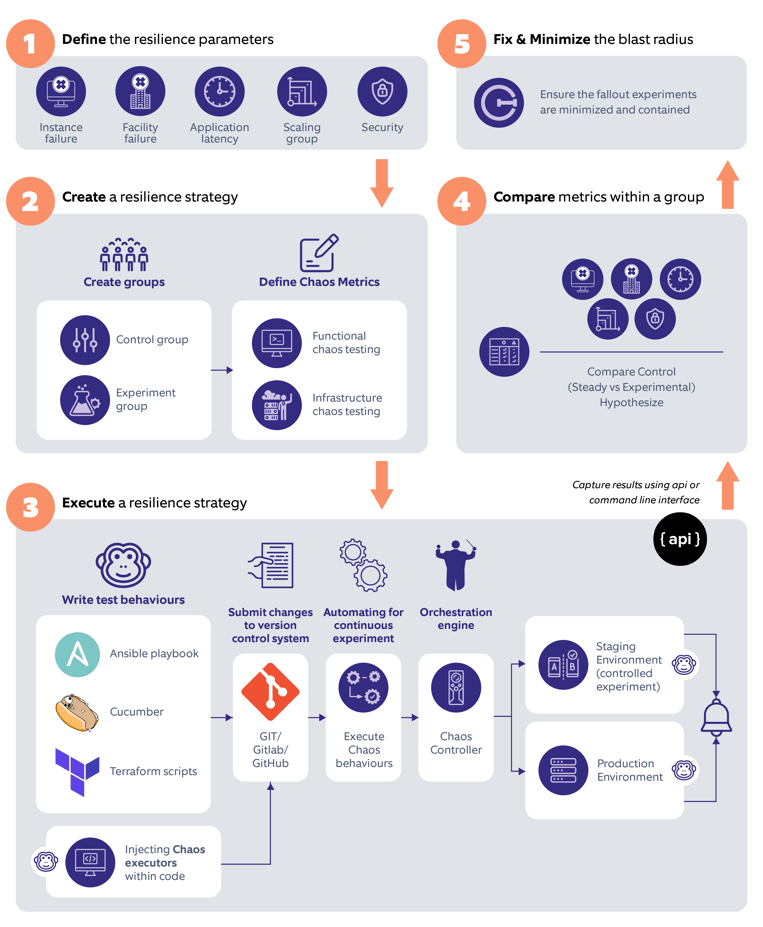
Follow these steps to provide a framework that will help any enterprise orchestrate chaos engineering smoothly:
Stage 01 - Define the resilience parameters
Understanding the scope of your experiment is of paramount importance. There can be many resilience testing levels and numerous areas where the system needs to be resilient. Just write down all the probabilities, for e.g., instance failure, facility failure, application latency impact, scaling issues, security issues, etc. After defining the different parameters, list them as per their business priorities. If you need help with prioritizing, use a scoring mechanism based on parameters such as a failover mechanism for the selected module, impact on overall performance, customer impact, multiplier factor, etc. The DevOps maturity dashboard can provide real-time inputs to such queries in the long run. You must also keep in mind that the parameter you start with, should have minimal impact on the business so that you can build your strategy confidently.
Stage 02 - Create a resilience strategy
Categorize the listed resilience parameters into two groups:
- a control group, which will be the benchmark for the entire testing process
- an experimental group, where you will execute all the tests or experiments
After creating the groups, think about the different scenarios that can break the system around the resilience parameters. These possibilities could be related to the application (Functional chaos metrics) or the infrastructure (Infrastructure chaos metrics).
For example, if your resilience parameter is ‘instance failure’, the associated functional metrics could be:
- high hits on application
- memory leak from application
- a high volume of jobs running
Infrastructure metrics could be:
- disk failure
- network failure
- kernel panic, etc.
Stage 03 - Execute the resilience strategy
By now, you must be clear about the parameters that need to be tested for chaos engineering. This is the stage where you create and execute the chaos plan:
1. Start creating the chaos behavior that will be executed to simulate the experiment around the resilience parameters. Tools like Ansible can expedite the process because of their deep integration with many systems like VM, cloud providers, etc. You can also write a relatively modest application that will behave as a chaos simulator or nectar service, breaking the system internally or functionally around the resilience parameter. For example, the application started generating a lot of threads that could cause disk failure.
2. Place all your tests within a version control system like GIT, so that it can be integrated with your automated pipeline by following the GitOps approach.
3. To execute these scripts, DevOps recommends that all resilience testing modules should be a part of your continuous delivery pipeline. So, with every new feature, you can evaluate the resilience of your system. You can also execute them as independent modules with the help of Jenkin’s chaos pipeline.
4. The chaos controller module is the brain of the entire solution. It describes how much you need to execute and in which order. If you have just started in this area, you obviously don’t want to lose your customer’s trust. You don’t want every chaos to be executed randomly. You can use open-source tools or even write your own controller to get the tailored fit framework for restricted chaos execution. Once you have gained momentum, you can start doing it in real black box testing.
5. Finally, it’s time to run the resilience test over the staging environment, followed by the production environment execution in a limited or defined scope within the Chaos controller.
Stage 04 - Compare the metrics within a group
After executing the experiments, start collecting data from different systems – application logs, monitoring system, alert system, application API, database, etc. DevOps automation can help in collecting data from the aforementioned systems in real-time. This helps you to swiftly compare the substantial results of the control state group with the experimental state group. Visualization over simulation is a crucial implementation here, as it gives a more comprehensive analysis of the data over and above monitoring solutions like Grafana, Prometheus, or Kibana.
Stage 05 - Fix and minimize the blast radius
By now, you know what needs to be corrected in the architecture – whether it is your database to fix the data loss problem, requirement of dynamic infrastructure scaling, application fix to manage cache, or whether you need to strengthen your security modeling practice. If you think you have the fix ready and applied, start the entire cycle again. Once you have reduced the blast surface after applying the fixes and re-testing the parameter, pick the next one and follow suit till you are sure that your customers will never face a disruption again, at least for the defined parameters.
Nagarro’s framework from resilience testing to orchestrate chaos engineering
In a nutshell
Implementing the Chaos engineering discipline needs time and blue-sky thinking. At the same time, it will also evoke confidence. Confidence that your system can handle turbulence caused by any direct or indirect module/system within the entire ecosystem. This discipline cannot be built in a day. You have to walk the extra mile with perfection to build the brand advocates, irrespective of whether you are still on a legacy framework or on modern application framework. The Simian Army Project by Netflix gave us a new thought process to challenge our system with random failure mechanisms by using various system resilience tools. You should also build your framework along similar lines where the DevOps toolchain plays a pivotal role and where engineers focus on resilience testing. This will ensure that you can bring in a structured chaos engineering discipline within the organization for immaculate engineering.

