

 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)

It’s time for your annual get-away. Not so long ago, when Thomas Cook reigned as the supreme travel agent-in-chief, you had to book an appointment with a travel agent. The agent would then suggest the best tour package given your budget, group size, and the change in scenery you craved for. All you had to do was fork out the cash and the agent would work behind the scenes to make sure your vacation was going to be as hassle-free as possible.
Databases were just handwritten logbooks maintained at the agent’s desk. If you approached the agent for a room booking, he would call up the hotel reception who would then make an entry on your behalf at the hotel’s log (database). Simpler times. But, alas, you arrive at your hotel and notice that the entry has not in fact been made as you requested it to be. Your agent swears that the entry is made in his copy of the logbook. Looks like you’ve fallen victim to a database mismatch! Now, imagine all the database errors that could creep in if you had to keep track of hotel reservations, airline ticket bookings, and so on.
Thankfully, nowadays, from booking flight tickets to reserving beachside villas, everything is within your reach. Bid goodbye to being dependent on agents, just go online and hunt out the best deals. Now, the new problem is that you have to book your preferred hotel and airline through their own websites. Entrepreneurs cashed in on this inconvenience to come up with travel aggregator sites like Trivago and MakeMyTrip. Of course, all they’ve actually done is replace a flesh-and-blood travel agent with a binary equivalent. How then, can we ensure that this new digital assistant doesn’t cause the same lapses as its human counterpart? How will it keep track of what booking to make for which service?
What are Microservices?
If booking a vacation package is the service you seek, then each of its components like looking for a flight, reserving a hotel room, and booking the actual room are the microservices that make up the complete package. In fact, you can break it down even further.
Take the ticket purchase example. First, the application must ensure your account has sufficient balance to carry out the transaction. Then it needs to book a seat for the required date. Next, the money should be debited from your account and transferred to the airline’s account. Finally, the airline has to confirm that the transaction has been carried out successfully. Whew! That’s a whole lot of microservices and a gamut of potential failures waiting to happen.
It’s Actually a Bit More Intricate Than That
Now, consider the typical architecture of a monolithic server-side application. That’s what we’ve been talking about so far. In a monolithic application, you have:
- A presentation layer responsible for handling requests, which is the layer that a user typically sees
- A business logic layer where the applications’ business logic resides
- A database layer to store request and an application integration layer so that the application can be integrated with other services
While this monolithic architecture is easy to develop, test, and deploy, it comes with its own set of disadvantages. Once the application gets too large and complex, it becomes difficult to make changes fast and accurately. This is when the travel agent at Thomas Cook goes “Blimey! That’s a lot of data for me logbooks!”
Monolithic applications have a logically modular structure, as seen in the different layers for database, business logic, etc. The key here is that they are only logically modular. When it comes to scaling the applications or, in other words, ramping up the processed transactions, this modularity can cause conflicts in resource requirements. Additionally, continuous deployment is also difficult for monolithic applications. You must redeploy the entire application after each update. That is like saying if our travel agent makes a wrong entry, he has to burn his book and re-write the whole thing again. A bug in any module also becomes problematic for the entire application.
It became a necessity to have a multi-layered architecture, where each layer was isolated from issues plaguing other layers and could be updated without worrying about database mismatch. Both our receptionist and travel agent need to have the same copy of the logbook. And thus, very organically and out of industry requirements, the microservices architecture (MSA) came into being. Given the scale of how big web applications were poised to become, MSA couldn’t have come any sooner.
Simply put, microservices architecture is a portable and self-containing unit of work, kept separate from the application. According to a paper published by IEEE, it structures an application as a collection of loosely coupled services.
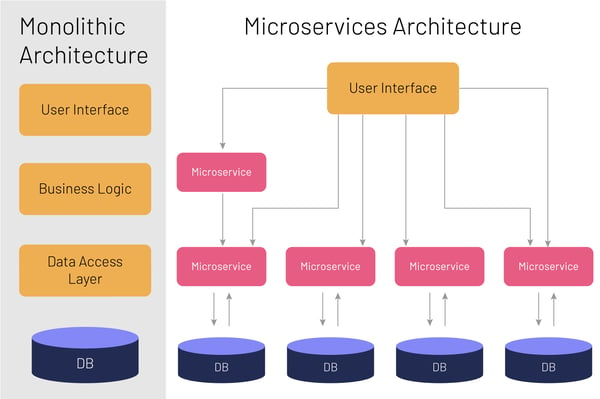
An example, cited by inforworld.com is that of eBay. In 2006, eBay created separate Java servlet applications that handled users, items, accounts, feedback, transactions, and more than 70 other elements. Each of those logical functional applications is a microservice. Since microservices do not share a data layer, each has its own load balancers and databases. In the same application, one microservice could use a relational database while another uses NoSQL database.
If you think about it, building applications this way – with different layers residing in different silos – is a no-brainer. Even if one layer succumbs to a bug, the other layers remain unaffected. The infected layer can be patched without worrying about how this might cause other bugs to pop up in other, unrelated layers.
Databases in Microservices Architecture
Despite its numerous advantages, developers face some issues when they decide to switch over to an MSA for their application. As an example, take the case of booking a travel ticket. To give a high-level view, in a monolithic architecture, once the buyer sends the ‘buy ticket’ action, the service needs to ensure that there are sufficient funds to carry out the transaction. This is followed by checking for availability and then confirming the booking. For each of these, the system will create a unique database transaction that can work across multiple database tables. If any step fails, the transaction will be rolled back and the database integrity will be maintained.
Before we get back to this, let’s examine what database integrity means. The term ‘data integrity’ refers to the accuracy and consistency of data. Database integrity refers to a database that is optimized to maintain this data integrity. One framework that is universally accepted to enforce this is ACID. ACID stands for Atomicity, Consistency, Isolation, and Durability.
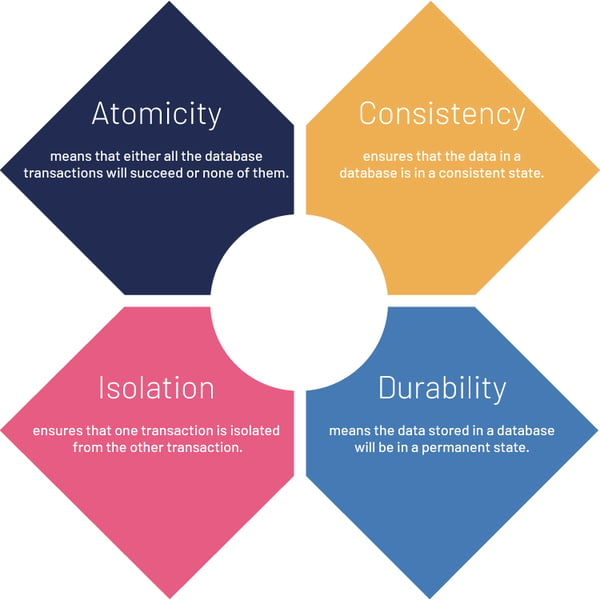
Atomicity means that a transaction must exhibit an ‘all or nothing’ behavior. It’s either all the instructions within a transaction that are executed or none of them. In the case of our ticketing example, if either money fails to be debited from the bank or confirmation is not received, the entire process should be marked as failed. This mechanism works well for our monolithic system.
Now, let’s break this transaction into BuyMicroservice and BankMicroservice. The actions leading up to the confirmation of the ticket purchase are now segregated into these two microservice silos. For example, the buy action and sending a request to the bank to debit the account could be in one microservice, while actually debiting the money from the bank and sending the confirmation could be in the other microservice. In this case, when the buyer initiated the action, both microservices will be called to apply changes to their own respective database tables. This is called a distributed transaction.
Distributed transaction means the breaking down of logical transactions of the monolithic architecture into multiple services (popularly known as distributed) that will be called in a sequence. Now that our monolithic database has been converted to a distributed database, each microservice should have its own private database. No microservice should be capable of modifying databases not belonging to its own domain.
Atomicity in Microservices Architecture
The question that arises now is: how do we ensure atomicity when it comes to distributed databases? As mentioned earlier, atomicity means that either every step in a transaction succeeds or the entire transaction is rolled back. In our example, let us assume that BankMicroservice has failed. So how do we roll back BuyMicroservice?
This is an important issue, especially for microservices, since there is no other way to find out if a transaction has been completed. Here are two patterns that can resolve this problem:
2pc/Two-phase Commit Pattern
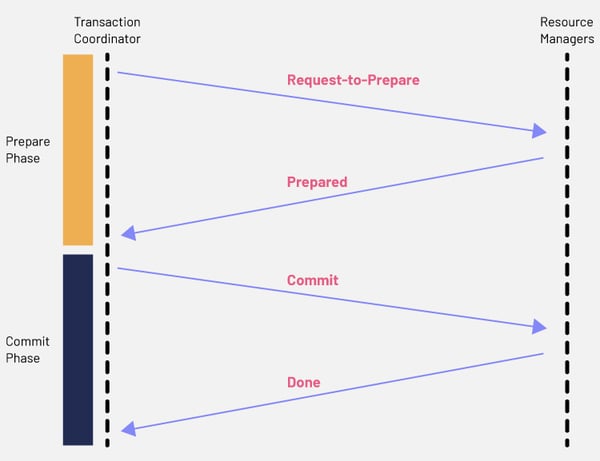
Widely used in database systems, 2pc can also be used within microservice architectures, albeit with some limitations. Two-phase commit is a commonly used pattern in distributed transactions. It works in two phases – prepare and commit. In the prepare phase, all microservices are asked to prepare the data to be committed. Once this data is prepared, the commit phase will ask the microservices to implement the actual changes. In this pattern, a global coordinator maintains the transaction lifecycle and controls the microservices to prepare and commit.
For example, in our earlier case, when the user sends the buy request, the global coordinator will first create a global transaction with all the context information. It will then direct the BuyMicroservice to prepare itself for initiating the transaction. BuyMicroservice, in turn, will check its internal parameters and confirm if it is prepared to go forward with the transaction. The same process is repeated with BankMicroservice. Once all microservices have confirmed with the global coordinator, they will then be asked to apply the changes to their databases through a commit request.
However, if BankMicroservice has already confirmed its status as ‘prepared’ but BuyMicroservice has ‘failed’, the coordinator will request an abort on BankMicroservice and it will roll back any changes.
Messages in a two-phase commit typically follow this flow:
Step 1a: The coordinator sends a query to commit.
Step 1b: Participant (microservice) receives the query.
Step 2a: The microservice votes yes (prepared) or no (abort).
Step 2b: The coordinator receives either prepare or abort.
Step 3: The coordinator sends a query to commit or rollback.
Step 3a: The microservice acknowledges.
END
No doubt, this pattern offers consistency as it first prepares and then commits the data. This ensures transaction atomicity and read-write isolation. However, when it comes to microservices, this protocol is not preferred because it is synchronous in nature. This means that the protocol will lock the object before the transaction is completed.
Databases are often integrated with other external systems and this lock-in period could turn out to be a bottleneck.
The Saga Pattern
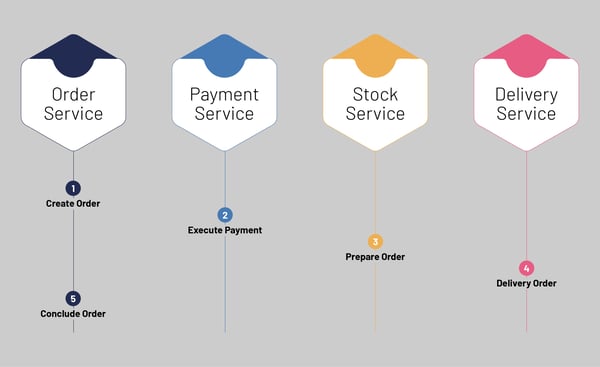
This brings us to the Saga pattern – an asynchronous and reactive pattern widely used for distributed transactions. The Saga pattern offers communication with other microservices via the Saga log. In this pattern, if any microservice fails to execute its local transaction, another microservice will execute a compensating transaction to roll back the changes. In our case, if the BuyMicroservice is executed successfully, the BankMicroservice will look for a signal about the same and will execute its tasks. If the BuyMicroservice has failed in its task, the BankMicroservice will instead perform a task to roll back any changes by the preceding microservices. To summarize, the first transaction is initiated by an external request corresponding to the system operation, and each subsequent step is then triggered by the completion of the previous one.
This is advantageous, especially for long-lived transactions. However, implementing the Saga pattern is not easy when multiple microservices are involved. To address the complexities in the Saga pattern, an orchestrator listens to the events and triggering endpoints. The orchestrator is a service that has the sole responsibility of telling each participant what to do and when.
The Saga pattern is the preferred method of solving distribution transaction problems in a microservice-based design. However, the programming model gets more complex due to the increase in your infrastructure complexity and this introduces its own unique set of obstacles.
In Conclusion
Apart from enabling enterprises to respond quickly to changing market trends, the microservices architecture also maximizes deployment velocity and ensures a continuous delivery cycle with minimal to zero downtime. This helps developers to produce superior quality software products and reduces costs to the company as well.
The advantages of adopting a microservices architecture are clear. But every enterprise needs to ensure database ATOM-icity when moving to an MSA. Depending on your organization’s average transaction size and architecture complexity, stakeholders can decide between a Two-phase commit pattern or the Saga pattern to make the right choice.

