

Discover more about us,
an outstanding digital
solutions developer and a
great place to work in.
 China
China  India
India  Japan
Japan  Philippines
Philippines  Singapore
Singapore  South Africa
South Africa  Sri Lanka
Sri Lanka  Thailand
Thailand  Colombia
Colombia  Ecuador
Ecuador  Austria
Austria  Denmark
Denmark  Finland
Finland  France
France  Germany
Germany  Hungary
Hungary  Norway
Norway  Poland
Poland  Portugal
Portugal  Romania
Romania  Spain
Spain  Sweden
Sweden  Switzerland
Switzerland  United Kingdom
United Kingdom  UAE
UAE  Canada
Canada  Mexico
Mexico  United States
United States .svg)


Let’s say your customer is in the middle of an online transaction. The customer is either transferring funds through internet banking, executing a stock market transaction, or withdrawing cash at the ATM. And suddenly, the website crashes, or there is an unexpected power outage at the bank’s data center or the system breaks. The money does get deducted, but the transaction fails. Consequence? Lost revenue, a frustrated customer, grim user sentiment, and damage to the brand’s reputation.
A system outage or failure to protect customer data can significantly impact any enterprise's finances and reputation. In large-scale organizations, with changes happening at scale across multiple departments, workflows, and chains of command, these risks can multiply quickly. More so in the Banking, Financial Services, and Insurance (BFSI) industry, where not only customer data also but their money and sentiments are involved.
In addition to the pressure to provide seamless services to the customers, financial institutions, including banks, insurance companies, and trading applications, also face the challenge of meeting compliance regulations that are essential to ensure data privacy and strengthen operational resilience.
For instance, in the United States, Federal Financial Institutions Examination Council (FFIEC) have issued a directive to protect consumer financial information through managed firewalls, security monitoring, as well as managed intrusion detection & intrusion prevention. Similarly, Strong Customer Authentication (SCA) is a European regulatory requirement. Any failure to comply with these standards leads to heavy fines and penalties for financial institutions.
How can technology help build reliable systems that meet customer expectations in the fast-paced, competitive BFSI industry? The answer lies in digital resilience that helps companies build robust systems and deliver an enhanced customer experience with greater accessibility. You can build resilience in complex business ecosystems with reliability testing and be confident that they withstand failures and outages.
Importance of Reliability Testing for Banking and Payments
Whether you are a banker, lender, or insurance service provider, your customers expect you to provide them with technology systems that are fast, always functional, safe, and reliable. Network outages, system failures, and drops in performance not only affect their experience but can compromise commitments to service level agreements (SLAs) and regulatory compliance. One of the best ways to improve the overall reliability of the systems and services is by implementing chaos engineering. This keeps the services under control, which would otherwise result in an outage.
To provide robust payment experiences, here’s a reference architecture that helps modularize and align business and technology assets in a predictable way.
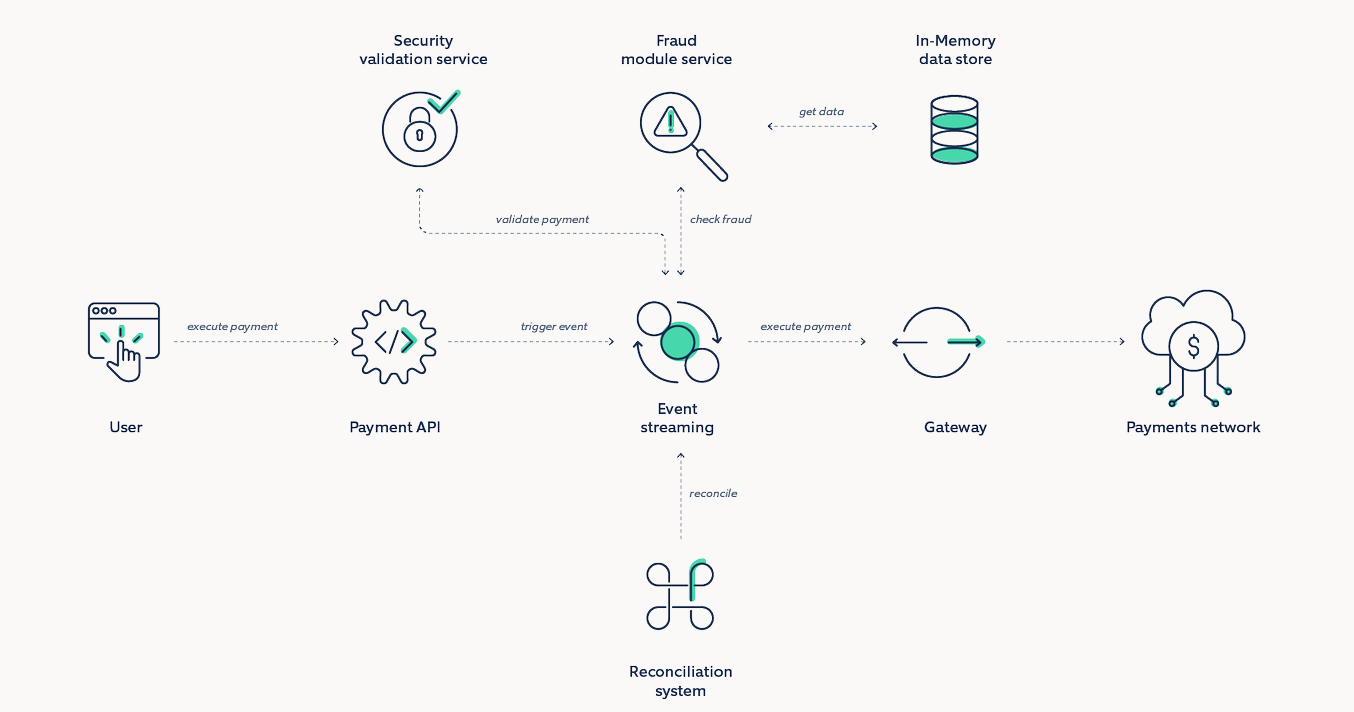
Let us look at a few scenarios where we can test the resiliency and reliability of the above architecture:
| Serial No. | Component | Indicative Technology | Test Scenario | Chaos Experiment | Expected Result |
| 1 | Event Streaming | Kafka |
Risk of data loss due to dropped messages. The leader broker fails before follower brokers can replicate the messages. |
Using a blackhole attack to simulate a leader broker outage. | A few messages will be lost due to the leader failing, but Kafka should quickly elect a new leader and successfully replicate messages again. |
| 2 | Event Streaming | Kafka | Data inconsistency & data corruption | Using a shutdown to restart a majority of broker nodes. | The remaining online broker should be elected as the new controller. Kafka will experience a temporary stop in throughput, but broker nodes should rejoin the cluster without issue. |
| 3 | Event Streaming | Kafka |
Tolerance of ZooKeeper outage |
Using a blackhole attack to drop all traffic to and from our ZooKeeper nodes to simulate an Apache ZooKeeper outage |
Verify there are no cascading failures, and the Kafka cluster can survive an unexpected ZooKeeper outage without failing, losing data, or corrupting data. |
| 4 | In-memory data store | Redis |
Fault tolerance and high availability |
Kill a data grid node within cluster or kill a cluster completely. |
Other nodes should be able to serve the traffic till the killed node rejoins. |
| 5 | In-memory data store | Redis | Measure latency | Inject latency to the Data Grid host. | There should be no impact on caching performance. |
| 6 | Payment API | MuleSoft/Apigee | Validating load balancing and automatic failover of backend services through health checks | Use a blackhole attack to drop all network traffic between API gateway and one of the backend worker instances. | There should be no failed requests. All requests should be forwarded to the healthy instance. If any requests fail because the gateway can’t contact the backend, then we know we need to reconfigure our health checks. |
| 7 | Fraud/Security microservices | Kubernetes |
Service dependencies and timeouts. Verifying dependencies and how application mitigates those failures |
Inject latency/blackhole between microservice calls. | Timeouts between service calls are defined and is consistent. Retry logic is implemented to overcome intermittent failures |
| 8 | Fraud/Security microservices | Kubernetes | Validating auto scaling parameters and implementation | Inject CPU/Memory Hog in nodes and simulate traffic/load. | Validate that the additional pods are spun up as per defined auto scaling parameters and there are no request fails. |
| 9 | Fraud/Security microservices | Kubernetes | Deployment Sanity. Replica availability & uninterrupted service | Kill containers. | Containers should be recovered automatically and there should be no impact to end users. |
*The scenarios and experiments listed above are not exhaustive and indicative in nature. They depend on varying factors such as technology components, deployment architecture, infrastructure components, etc.
Read our blog to know how you can pilot chaos engineering experiments on a Kubernetes cluster.
Benefits of Reliability Testing for BFSI industry
When resilience is not kept on priority, core business components become vulnerable to cyberattacks. By building resilience, financial institutions get visibility of processes and crucial assets, which prepares them for instances of any unforeseen failures of a process or service. Listed below are the ways reliability testing can help improve the resilience of financial IT systems:
1. Prevent cascading outages by:
- testing redundant and fault-tolerant patterns of the architecture
- continuously verifying resilient behavior in production
2. Build assurance in your critical metrics by:
- creating test scenarios that validate the presence/absence of appropriate detection behaviors while measuring Mean-Time-To-Detect (MTTD) a failure
- observing recovery behaviors and measuring Mean-Time-To-Recover (MTTR)
- reducing time to onboard new team members
3. Ensure compliance with SLA and regulatory guidelines by:
- measuring service level resilience scores and uptime metrics
- continuously improving the design and capacity planning of infrastructure components
- designing graceful degradation strategies to provide it just works like experience
- running gamedays that democratize knowledge of architecture across team members
- making the entire ecosystem inherently resilient to failures through sharing of best practices
- creating robust documentation
What Nagarro brings to the table?
Are your systems prepared for any unexpected outages? Are you confident enough to upgrade to new systems without any downtime? Is your team prepared for disaster recovery during an outage (from failover to a backup)?
If your answer is no to any of these questions, Nagarro can help you strengthen digital resilience, deliver uninterrupted services against outages, predict unanticipated surges in traffic volumes as well as prevent cybersecurity attacks. Learn more about our Resilience Engineering services.

tags


